首页 > 电子期刊 > J > 计算机时代
基于网络爬虫原理的Web内容挖掘技术分析
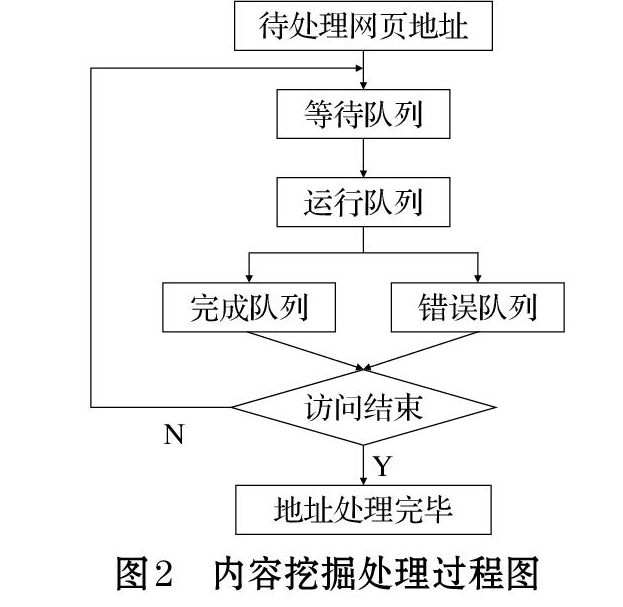
需经过三个流程[7]。这四个队列如下:⑴ 等待队列是爬虫初始网页地址和爬虫程序新发现的网页地址的集合;⑵ 运行队列是爬虫程序正在处理的网页地址的集合;⑶ 完成队列是已经被爬行完成的网页地址的集合;⑷ 错误队列是爬虫程序在解析页面出错或读取数据超时网页地址的集合。网络爬虫程序在<<上一页 下一页>>
广州市越秀区图书馆版权所有。 联系电话:020-87673002
本站访问人数: