首页 > 电子期刊 > J > 计算机时代
基于网络爬虫原理的Web内容挖掘技术分析
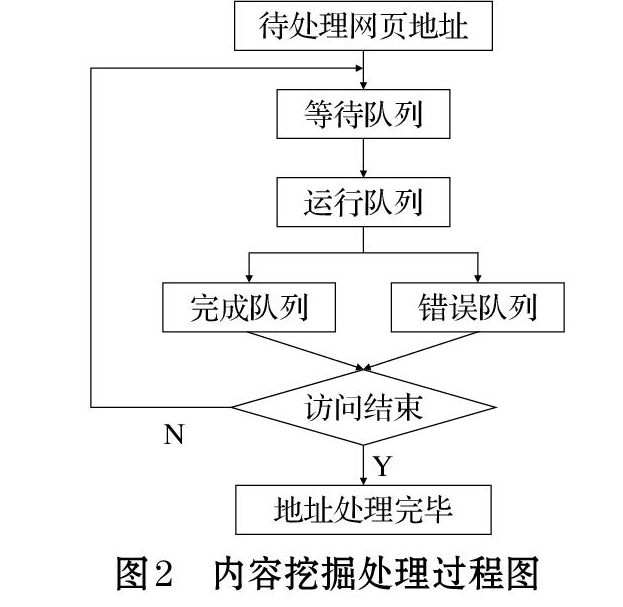
页的程序,它为搜索引擎从万维网下载网页,是搜索引擎的重要组成部分。一个商业网站的Web页面是以超链接的关系存在的,这就组成了类似一张张的网。网络爬虫是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,同时找到在网页中的其他链接地址,通过这<<上一页 下一页>>
广州市越秀区图书馆版权所有。 联系电话:020-87673002
本站访问人数: