首页 > 电子期刊 > J > 计算机时代
基于网络爬虫原理的Web内容挖掘技术分析
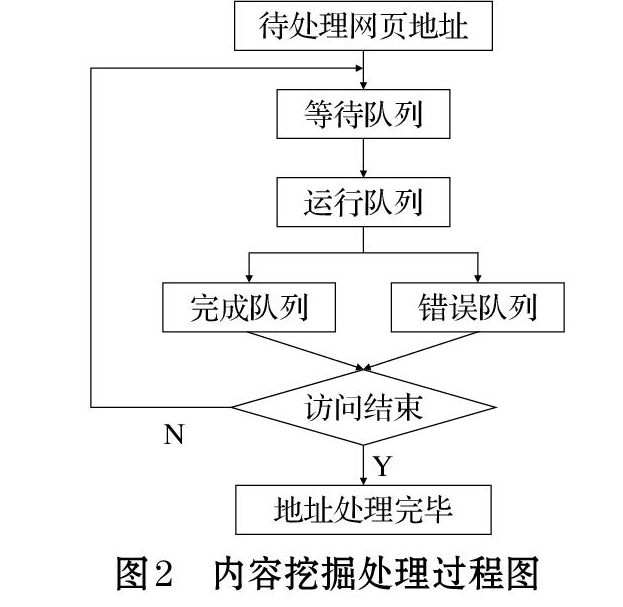
些链接地址寻找下一个网页,这样一直循环下去,最终把这个网站所有的网页都抓取完为止[5]。假设把整个互联网当成一张网,那么网络爬虫就可以用这个原理在这张网上把互联网上所有的网页信息都抓取下来。具体可按如下步骤。Step1:从一个或若干初始网页的网页地址开始,获得初始网页上的网页<<上一页 下一页>>
广州市越秀区图书馆版权所有。 联系电话:020-87673002
本站访问人数: