首页 > 电子期刊 > J > 计算机时代
基于网络爬虫原理的Web内容挖掘技术分析
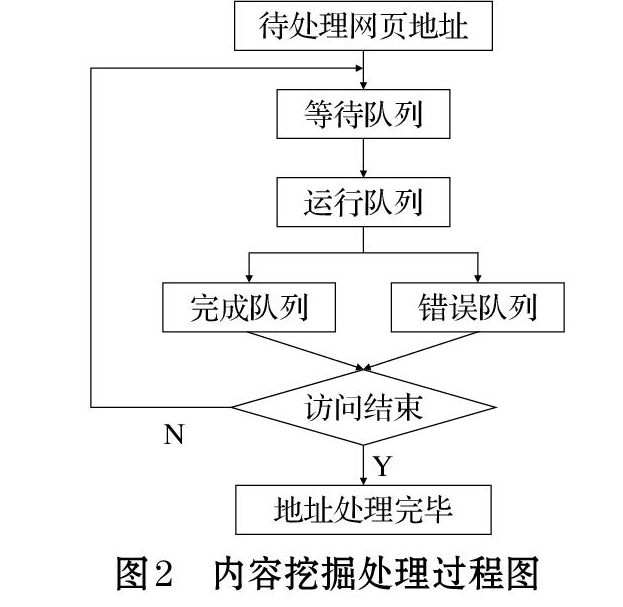
地址;Step2:不断从当前页面上抽取新的地址放入队列,直到满足系统的一定条件才停止。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的地址队列;Step3:根据一定的搜索策略从队列中选择下一步要抓取的网页地址;Setp4:不<<上一页 下一页>>
广州市越秀区图书馆版权所有。 联系电话:020-87673002
本站访问人数: