首页 > 电子期刊 > J > 计算机时代
基于网络爬虫原理的Web内容挖掘技术分析
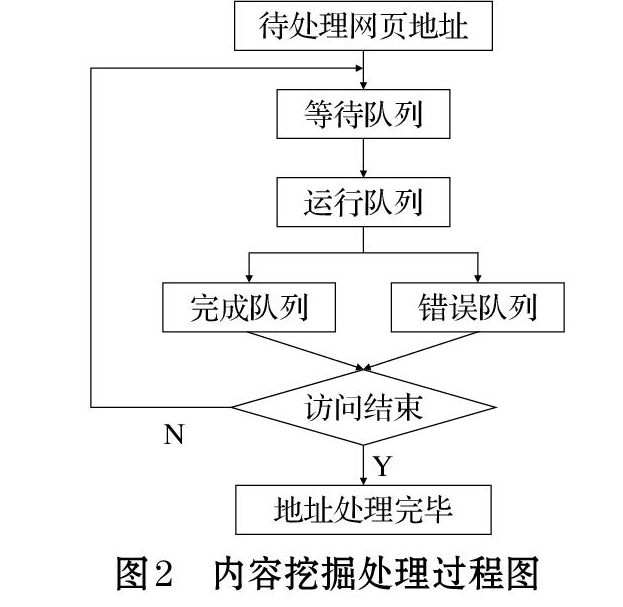
断重复步骤2-3,直到达到系统的某个条件发出停止指令,不再往下访问;Setp5:将所有被爬虫抓取的网页存贮,并进行一定的分析、过滤,并建立索引,以便之后的查询和检索。对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导;Setp6:任务完成。3 基于爬虫内容挖<<上一页 下一页>>
广州市越秀区图书馆版权所有。 联系电话:020-87673002
本站访问人数: